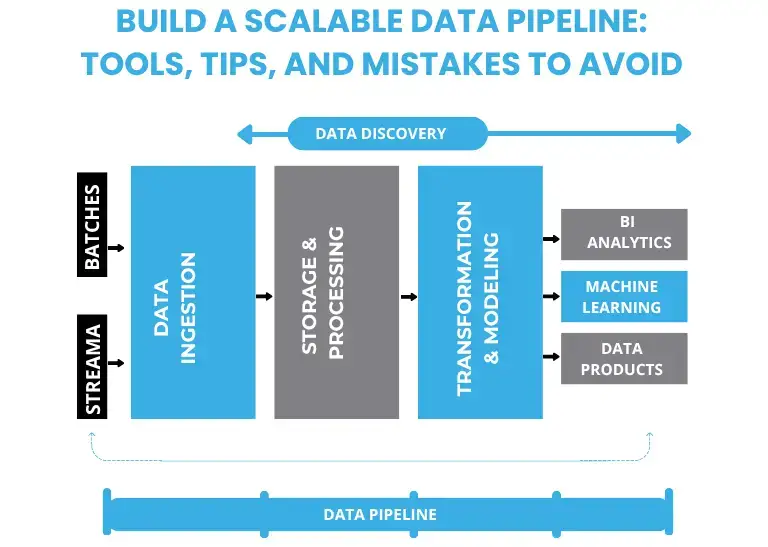
Build a Scalable Data Pipeline: Tools, Tips, and Mistakes to Avoid
At Cruz Street, our mission is to empower organizations to harness data science to solve strategic problems and accelerate growth. When it comes to delivering insights at scale, a well-designed data pipeline isn’t just helpful—it’s foundational.
We sat down with Jon, our Lead Data Engineer, and Sean, Data Analyst, to talk shop about what goes into building scalable, resilient data pipelines and what mistakes to avoid along the way.
Start with the End in Mind
“If that end product is a BI tool or dashboard, then analysts need to be involved from day one.”
— Sean Crimmin, Data Analyst
A scalable pipeline is only as useful as the insights it delivers. That’s why our data pipeline architecture begins with collaboration between engineers and analysts. Before the first line of code is written, we define KPIs, reporting needs, and user expectations. This intentionality saves time, reduces rework, and ensures the final product meets stakeholder goals.
Selecting Pipeline and ETL Tools
We generally take an AWS-native approach to building scalable pipelines. While there are powerful tools from Microsoft, Google, and others, the AWS suite remains the most commonly adopted due to its depth, flexibility, and seamless integration. Jon emphasizes modularity and event-driven design within this ecosystem to ensure both reliability and performance. This approach gives us granular control over data movement and transformation. That’s something no code platforms often sacrifice. Here’s the stack we often use:
- Amazon S3
Raw data landing zone. Scalable, durable, cost effective. - AWS Glue
Handles ETL transformation, cleaning, and enrichment - Glue Data Catalog
Maintains schema definitions and metadata - Amazon Athena
Enables SQL querying over structured datasets - Amazon QuickSight with SPICE
Fast, self-serve dashboards with subsecond refresh - Amazon CloudWatch
Full observability and cost monitoring - AWS Step Functions
Manages parallel processing and error handling
Avoiding Common Pitfalls
Even seasoned teams hit roadblocks. Here are some issues we’ve encountered and how we’ve solved them.
❌ Mistake: Monolithic, All in One Tables
“The first pipeline I worked on tried to join everything into one table. It created logic issues, duplicate rows, and a maintenance nightmare.”
— Sean Crimmin
Fix: Build from clean, reusable base tables. Join them via SQL before visualization, not inside the pipeline.
❌ Mistake: Skipping Modular Design
When everything is bundled together, even a small failure can halt the whole system. Modular architecture creates fault boundaries and allows for efficient scaling and unit testing.
❌ Mistake: Failing to Flatten JSON Early
“BI tools don’t like nested JSON. If you skip normalization, you’ll be debugging visuals later.”
— Sean Crimmin
Fix: Normalize and flatten nested data as close to ingestion as possible.
Best Practices for Long Term Scalability
✅ Design for Change
Use event driven triggers like EventBridge and S3 and infrastructure that supports autoscaling.
✅ Validate with Prototypes
Create sample dashboards to test metrics and performance before scaling up.
✅ Data Governance
Use Glue Catalogs, document data quality rules, and track schema changes.
✅ End to End Monitoring
Log everything, alert on failures, and use dashboards for observability.
✅ Always Keep the End User in Mind
Uniform naming, clean data, and clarity in visuals matter just as much as backend architecture.
Final Thought
“Everything breaks eventually. What matters is how you plan for it.”
— Jon Brewer, Lead Data Engineer
Whether you’re dealing with terabytes of sensor data or real time customer metrics, the right architecture and a collaborative mindset can make all the difference.
We’ve built, tested, broken, and rebuilt dozens of data pipelines across industries. If you’re looking to build one that can scale with your business, learn from our experience and avoid the same traps.


